
 질문답변
질문답변질문답변 목록
Thirteen Hidden Open-Supply Libraries to Turn into an AI Wizard
페이지 정보
작성자 Gus 조회353회 댓글0건 작성일25-03-07 00:26본문
 Does DeepSeek AI Content Detector work for all AI-generated textual content? Use a browser-based content blocker, like AdGuard. On the earth of artificial intelligence, a new contender has emerged, challenging the dominance of established giants like ChatGPT. It does not get caught like GPT4o. I frankly do not get why people were even using GPT4o for code, I had realised in first 2-three days of utilization that it sucked for even mildly complex tasks and i stuck to GPT-4/Opus. 4o right here, where it will get too blind even with suggestions. As identified by Alex right here, Sonnet passed 64% of exams on their inside evals for agentic capabilities as in comparison with 38% for Opus. Maybe next gen fashions are gonna have agentic capabilities in weights. This sucks. Almost appears like they're changing the quantisation of the model in the background. Sometimes, you will discover foolish errors on issues that require arithmetic/ mathematical thinking (think data structure and algorithm issues), something like GPT4o. The DeepSeek cellular app does some really silly things, like plain-text HTTP for the registration sequence.
Does DeepSeek AI Content Detector work for all AI-generated textual content? Use a browser-based content blocker, like AdGuard. On the earth of artificial intelligence, a new contender has emerged, challenging the dominance of established giants like ChatGPT. It does not get caught like GPT4o. I frankly do not get why people were even using GPT4o for code, I had realised in first 2-three days of utilization that it sucked for even mildly complex tasks and i stuck to GPT-4/Opus. 4o right here, where it will get too blind even with suggestions. As identified by Alex right here, Sonnet passed 64% of exams on their inside evals for agentic capabilities as in comparison with 38% for Opus. Maybe next gen fashions are gonna have agentic capabilities in weights. This sucks. Almost appears like they're changing the quantisation of the model in the background. Sometimes, you will discover foolish errors on issues that require arithmetic/ mathematical thinking (think data structure and algorithm issues), something like GPT4o. The DeepSeek cellular app does some really silly things, like plain-text HTTP for the registration sequence.
I requested it to make the identical app I wanted gpt4o to make that it totally failed at. The feedback got here during the question part of Apple's 2025 first-quarter earnings call when an analyst asked Cook about DeepSeek and Apple's view. However, NVIDIA chief Jensen Huang, throughout the latest earnings call, mentioned the company’s inference demand is accelerating, fuelled by check-time scaling and new reasoning fashions. However, the size of the models were small in comparison with the scale of the github-code-clean dataset, and we were randomly sampling this dataset to provide the datasets used in our investigations. The mannequin additionally undergoes supervised high quality-tuning, the place it is taught to perform well on a particular process by coaching it on a labeled dataset. GPQA change is noticeable at 59.4%. GPQA, or Graduate-Level Google-Proof Q&A Benchmark, is a difficult dataset that accommodates MCQs from physics, chem, bio crafted by "area specialists". The upside is that they are usually extra dependable in domains such as physics, science, and math. Anyways coming again to Sonnet, Nat Friedman tweeted that we may have new benchmarks as a result of 96.4% (0 shot chain of thought) on GSM8K (grade school math benchmark). One risk is that advanced AI capabilities may now be achievable without the massive amount of computational power, microchips, power and cooling water previously thought obligatory.
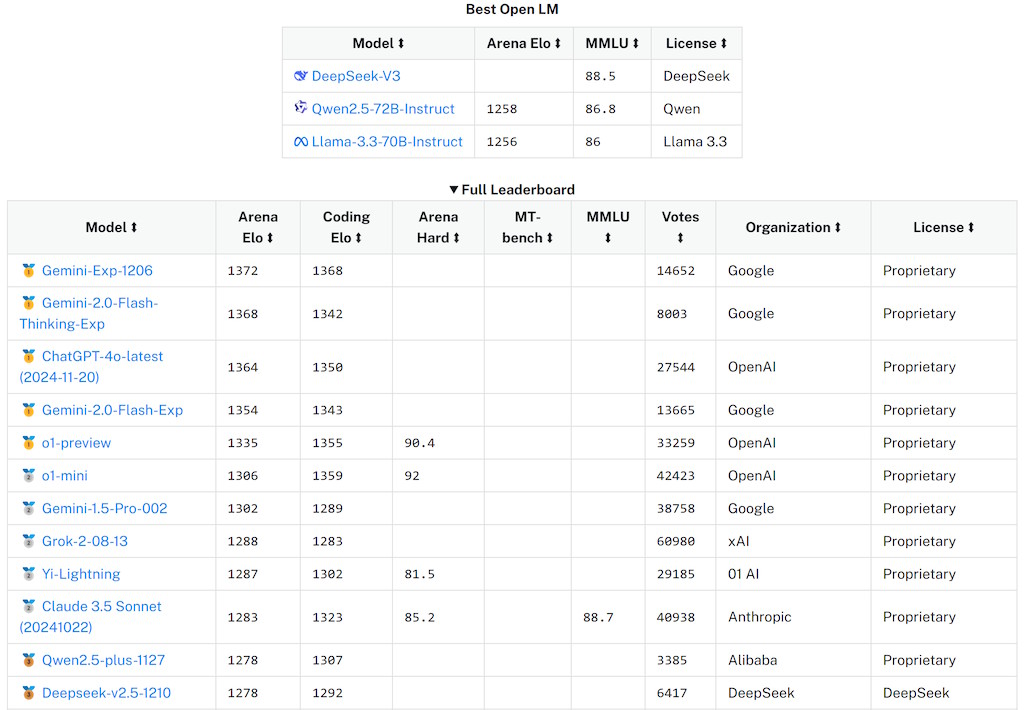 Sonnet now outperforms competitor models on key evaluations, at twice the velocity of Claude three Opus and one-fifth the fee. 4️⃣ Inoreader now supports Bluesky, so we are able to add search outcomes or follow users from an RSS reader. 1. needle: The string to search for inside the haystack. There might be benchmark data leakage/overfitting to benchmarks plus we don't know if our benchmarks are accurate sufficient for the SOTA LLMs. Thus far, my commentary has been that it could be a lazy at times or it would not understand what you are saying. You possibly can check here. Try CoT right here - "think step-by-step" or giving more detailed prompts. Oversimplifying right here however I believe you can not belief benchmarks blindly. I feel I love sonnet. I had some Jax code snippets which weren't working with Opus' help however Sonnet 3.5 fastened them in a single shot. Several individuals have seen that Sonnet 3.5 responds well to the "Make It Better" immediate for iteration.
Sonnet now outperforms competitor models on key evaluations, at twice the velocity of Claude three Opus and one-fifth the fee. 4️⃣ Inoreader now supports Bluesky, so we are able to add search outcomes or follow users from an RSS reader. 1. needle: The string to search for inside the haystack. There might be benchmark data leakage/overfitting to benchmarks plus we don't know if our benchmarks are accurate sufficient for the SOTA LLMs. Thus far, my commentary has been that it could be a lazy at times or it would not understand what you are saying. You possibly can check here. Try CoT right here - "think step-by-step" or giving more detailed prompts. Oversimplifying right here however I believe you can not belief benchmarks blindly. I feel I love sonnet. I had some Jax code snippets which weren't working with Opus' help however Sonnet 3.5 fastened them in a single shot. Several individuals have seen that Sonnet 3.5 responds well to the "Make It Better" immediate for iteration.
It does really feel much better at coding than GPT4o (cannot trust benchmarks for it haha) and noticeably higher than Opus. Experimentation with multi-choice questions has confirmed to reinforce benchmark efficiency, particularly in Chinese a number of-alternative benchmarks. Third, as mentioned above, these extra entity listings deal with the significant hole in allied controls on selling components to Chinese gear corporations. At CES 2025, Chinese firms showcased impressive robotics innovations. In January 2025, Western researchers had been in a position to trick DeepSeek into giving sure solutions to some of these topics by requesting in its answer to swap sure letters for similar-looking numbers. The outlet’s sources stated Microsoft safety researchers detected that massive amounts of knowledge were being exfiltrated by OpenAI developer accounts in late 2024, which the corporate believes are affiliated with Free DeepSeek online. Underrated factor but knowledge cutoff is April 2024. More reducing recent events, music/film recommendations, cutting edge code documentation, analysis paper knowledge support. This data included background investigations of American government staff who've top-secret safety clearances and do categorized work. Anthropic also launched an Artifacts characteristic which essentially provides you the choice to interact with code, lengthy documents, charts in a UI window to work with on the fitting facet.
If you cherished this article therefore you would like to be given more info pertaining to DeepSeek v3 (https://p.mobile9.com/) please visit our own web-page.
댓글목록
등록된 댓글이 없습니다.